Review: Databricks Lakehouse Platform
Databricks Lakehouse Platform combines cost-effective data storage with machine learning and data analytics, and it's available on AWS, Azure, and GCP. Could it be an affordable alternative for your data warehouse needs?






Contributor, InfoWorld |
- Getting started with Databricks Lakehouse
- Delta Lake
- Data science and engineering on Databricks Lakehouse
- Machine learning on Databricks Lakehouse
- SQL queries on Databricks Lakehouse
- Unity Catalog and Delta Sharing
 IDG
IDG
You can use a Spark SQL construction to convert a Parquet table to a Delta table.
The simplest SQL statement to convert to Delta format in place is CONVERT TO DELTA.
 IDG
IDG
You may also use the CONVERT TO DELTA statement.
Delta table stream capabilities take full advantage of Spark streams. Here, we see two streaming writes that are being appended to a table.
 IDG
IDG
Delta files can handle streams as well as static batch data.
The spark.readStream API can read and separate batch data and stream data, as shown by this display of 10-second window histograms.
 IDG
IDG
The spark.readStream API reads and separates batch data and stream data.
Delta tables support "time travel" version queries, restore from a previous version, schema enforcement, schema evolution, data manipulation language (DML) operations, and transaction history.
 IDG
IDG
The VERSION AS OF clause turns SELECT statements into historical version queries.
You can roll back to any version of a Delta table using the RESTORE
VERSION AS OF <n> SQL command. Here, we are rolling back to before the streams started.
 IDG
IDG
You can roll back to any version of a Delta table; in this case, we are rolling back to before the streams started.
You can't blithely change the schema of a Delta Lake table. Here, we attempt to add a column, but the Delta engine throws an analysis exception for the schema mismatch.
 IDG
IDG
The Delta engine throws an analysis exception.
Of course, sometimes you do want to change the schema. Delta Lake supports schema evolution using the mergeSchema option to the new_data.write.format command.
 IDG
IDG
Delta Lake supports schema evolution using the mergeSchema option to the new_data.write.format command.
Parquet and Apache ORC file formats don't support DML commands, but Delta Lake supports DELETE, UPDATE, and MERGE INTO. These commands are essential for complying with a mandated request to remove a user's personal information based on the General Data Protection Regulation and California Consumer Privacy Act.
 IDG
IDG
We can delete a specific loan ID using one line of standard SQL.
ACID transitions and the Delta Lake transaction log also support the time travel and DML features that we've just seen.
 IDG
IDG
The DESCRIBE HISTORY command displays the transaction log in a tabular format.
Machine learning on Databricks Lakehouse
Machine learning capabilities differentiate Databricks from some of its competitors:
Databricks Runtime ML clusters include the most popular machine learning libraries, such as TensorFlow, PyTorch, Keras, and XGBoost, and also include libraries required for distributed training such as Horovod. Using Databricks Runtime ML speeds up cluster creation and ensures that the installed library versions are compatible.
In addition, Databricks offers AutoML, Feature Store, pipelines, MLflow, and SHAP (SHapley Additive exPlanations) capabilities.
I went through a hands-on tutorial using Databricks Machine Learning to analyze a telco churn prediction problem. It starts with data exploration, which is standard. In this case the basic descriptive statistics don't tell us much.
 IDG
IDG
To start the churn analysis, we try basic descriptive statistics and data exploration. They're not very useful.
The analysis moves on to running AutoML with a limit of five models. We very quickly see results, but there isn't enough training data included (specifically, not enough columns) for a good model. As you'll see, in this story there's more data we can use, and several machine learning techniques for building a good model.
 IDG
IDG
A quick AutoML run gives us a best result using an XGBoost model. The best val F1 score is only 0.649, however. This needs more work.
Next, we try merging the existing training data with additional data from the Databricks Feature Store, which "just happened" to be left over from a previous analysis.
 IDG
IDG
The two tables are joined on the customerID column, the customerID column is excluded from the training set, and the table is saved in Delta format.
Using MLflow and scikit-learn, we fit the expanded training table to a LightGBM model and get an F1 score close to 0.8.
 IDG
IDG
With an F1 score close to 0.8, we're getting close.
A SHAP plot shows the relative impact of each variable on the model's prediction. SHAP is a post-fit XAI (explainable AI) technique.
 IDG
IDG
A SHAP plot shows the relative impact of each variable on the model's prediction.
t-Distributed Stochastic Neighbor Embedding (t-SNE) is an unsupervised, non-linear technique primarily used for data exploration and visualizing high-dimensional data. The PCA (principal component analysis) initialization does the dimensionality reduction. Note the obvious clustering patterns.
 IDG
IDG
t-Distributed Stochastic Neighbor Embedding (t-SNE) is an unsupervised, non-linear technique primarily used for data exploration and visualizing high-dimensional data.
Here, we fine-tune the model by using hyper-optimization to search for the best parameters.
 IDG
IDG
Fine-tuning the model with hyper-optimization.
We run a final experiment using the optimized parameters, and get an F1 score above 0.8.
 IDG
IDG
Our final experiment yields an F1 score above 0.8—success!
Finally, we test the accuracy score of the registered model. If it is at least 0.8, we can promote it to production in the model registry.
 IDG
IDG
Testing the accuracy score of the registered model.
SQL queries on Databricks Lakehouse
One of the features that makes Databricks Lakehouse Platform viable as a substitute for a standard data warehouse is its much improved SQL engine, called Photon. Photon is two to four times faster than Databricks' previous SQL engine, and was the SQL engine used in Databricks' stunning TPC-DS V3 benchmark results.
Using Databricks Photon SQL engine with spot instances brought the Price/Performance metric for a 100TB TPC-DS decision support benchmark down to $146, which is roughly 12 times better than the most expensive cloud data warehouse tested, and roughly 2.5 times better than the least expensive cloud data warehouse tested.
 IDG
IDG
Using Databricks Photon SQL engine with spot instances.
I went through a tutorial introduction to SQL on Databricks Lakehouse. This tutorial concentrated on building and running SQL queries, as opposed to the Python notebooks used in the first two tutorials.
One of the useful things you can build using Databricks Lakehouse Platform is a visualization based on an SQL query.
 IDG
IDG
This dashboard combines half a dozen visualizations and can be shared with others without granting them access to the data.
SQL endpoints are computation resources that run SQL queries. I used the provided starter endpoint.
 IDG
IDG
The provided starter endpoint: a single, small cluster.
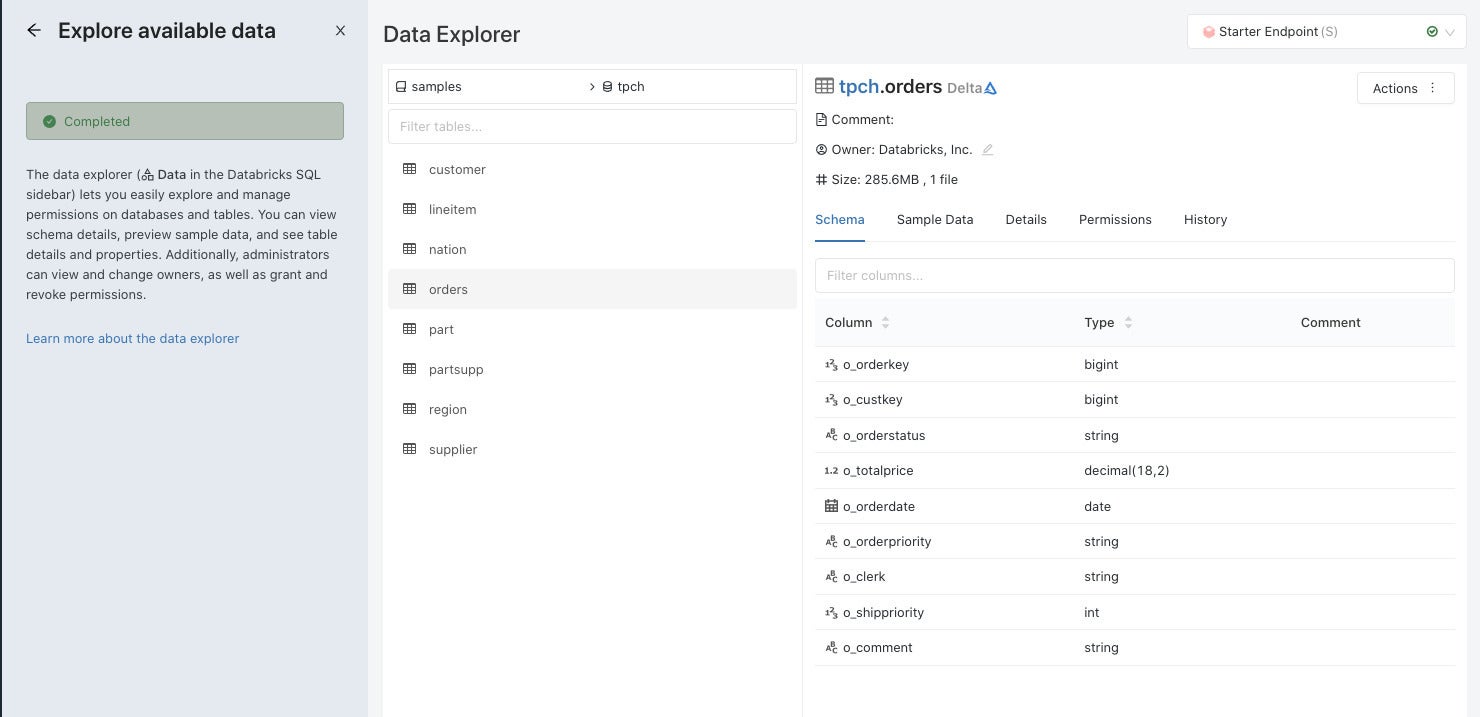
The Databricks SQL data explorer allows you to view your databases and tables, including the schema data shown here.
 IDG
IDG
Viewing databases and tables with the Databricks SQL data explorer.
This next screen shows the sample data for the file we used to view the schema in the previous screen.
 IDG
IDG
Sample data for the tpch.orders Delta file.
The Databricks SQL Editor is closely linked to the Data Explorer. In this next screen, we load and run a SELECT query against six of the tables in the tpch database.
 IDG
IDG
A query against tables in the tpch database lists the total national revenue by year and nation.
You can define one or more visualizations for each SQL query.
 IDG
IDG
This stacked bar chart appears in the visualization dashboard along with other visualizations.
Databricks SQL maintains a query history for you. Note that the SELECT year query we've been looking at took almost 30 seconds to run. Most of the other queries were generated by console actions.
 IDG
IDG
A sample query history.
Clicking on a query in the history brings up details about the query plan and timings.
 IDG
IDG
We can access details about the query plan and timing.
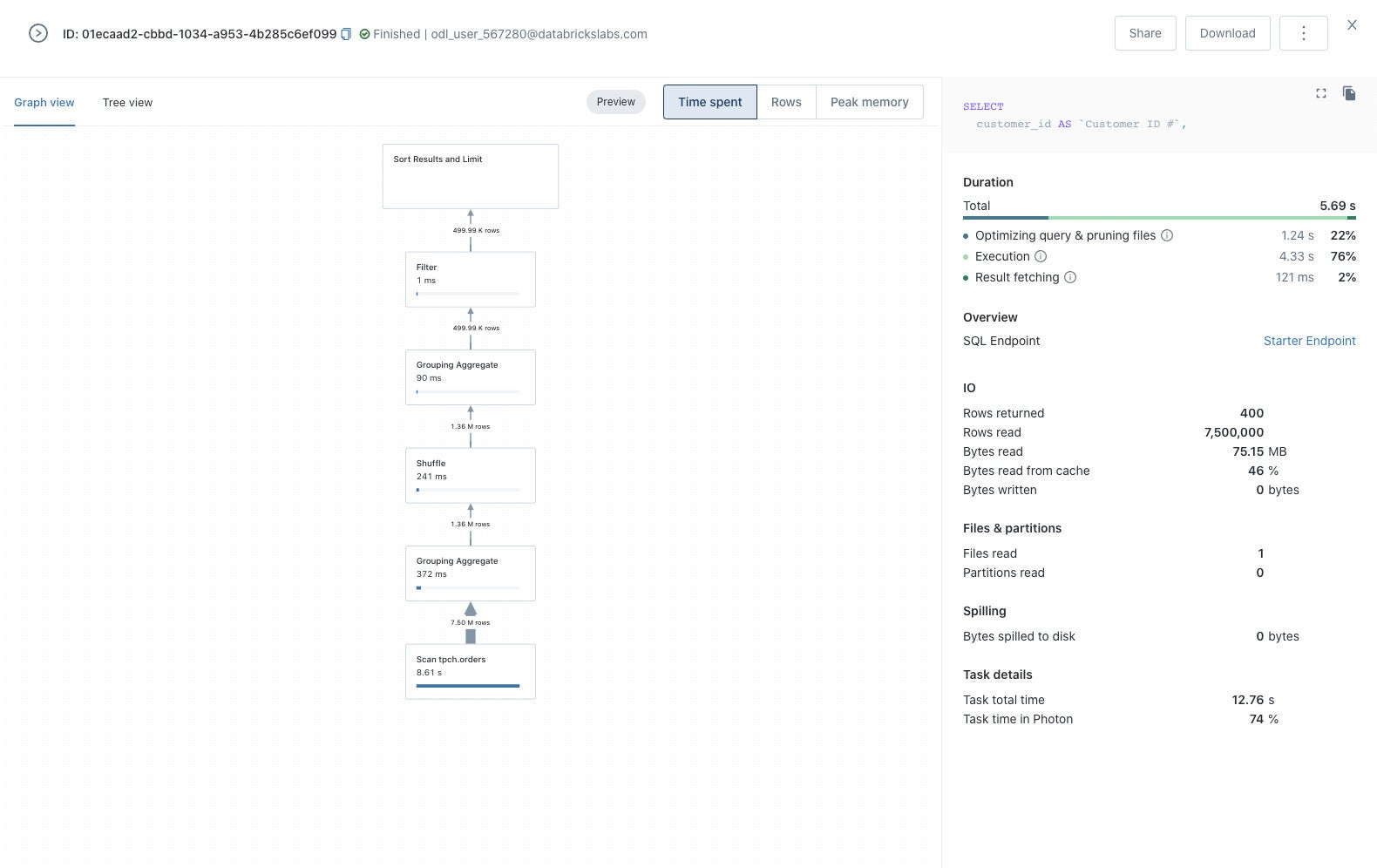
From the query details, we can bring up additional information such as a graph view of the query.
 IDG
IDG
We can also bring up a graph view of the query.
A tree view offers additional information.
 IDG
IDG
A tree view of the same query.
The monitoring screen for the SQL endpoint shows its utilization. The number of clusters here is only 1 or 0 because we didn't allow for more than one small cluster, which is appropriate for a single endpoint user (in this case, me).
 IDG
IDG
The monitoring screen for the SQL endpoint shows its utilization.
We can also define an alert tied to the results of an SQL query. This particular query is set to refresh every hour.
 IDG
IDG
We'll receive an alert if the top row of query results for revenue slides under $10 million.
Unity Catalog and Delta Sharing
The Azure Databricks Lakehouse that I reviewed did not include the Unity Catalog nor the Delta Sharing feature. Instead, Databricks gave me a demonstration of a pre-release version of both features on AWS.
Unity Catalog provides fine-grained governance for data and AI on Lakehouse. One result is that Databricks Lakehouse can actually be the single source of truth for your enterprise. Other benefits are access permissions for workloads, access management across clouds, and access controls on tables, files, rows, and columns. You also get visibility into data lineage (shown below) and fine-grained auditing of data consumption.
 IDG
IDG
A data lineage diagram courtesy of Unity Catalog.
Delta Sharing allows you to securely share live data across clouds, platforms, and on-prem without any data duplication. There's no more need to email data sets or post them on separate servers. A Delta Sharing server can interact with clients in all the major data tools and programming languages.
Conclusion
Overall, Databricks Lakehouse Platform is almost excellent as a data lake that can replace a data warehouse. It's not for everyone, however, and it's not quite feature complete.
To use Databricks Lakehouse effectively through its own interfaces, you need to know SQL and be able to program in at least one of its supported languages: Python, Scala, or R. The Databricks APIs allow other programs to control it, and some of those can serve as easy-to-use front ends, for example Tellius.
On the machine learning side, Databricks now supports most of the prominent machine learning and deep learning frameworks, in addition to its own machine learning libraries. It offers both AutoML and hyperparameter optimization to automate the machine learning process. That said, it's still best suited for data scientists: A business analyst without a background in statistics and machine learning could easily accept bad models as adequate, or have difficulty deciding how to improve weak models.
The promised Unity Catalog and Delta Sharing, which should improve governance and live data sharing, are not yet generally available, and not completely fleshed out. When both of these are finished and released, Databricks Lakehouse Platform should indeed be able to replace cloud data warehouses, but it will still be a platform best used by programmers and data scientists.
–
Cost: 14-day free trial (not including cloud infrastructure costs). Pricing is based on compute usage, with spot instance and committed usage discounts. You can choose pay-as-you-go or committed-use plans on AWS, Azure, and GCP.
Platform: Host on AWS, Azure, or GCP. Databricks Lakehouse Platform support numerous client IDEs, connectors, drivers, and APIs.
Copyright © 2022 IDG Communications, Inc.