Review: YugabyteDB does PostgreSQL proud
YugabyteDB 2.13 is a highly scalable, distributed version of PostgreSQL that combines compelling ideas from Google Cloud Spanner and Amazon Aurora—and serves as a Cassandra-compatible database too.






Contributor, InfoWorld |

-
YugabyteDB 2.13
When I reviewed YugaByteDB 1.0 in 2018, it combined distributed ACID transactions, multi-region deployment, and support for Cassandra and Redis APIs. At the time, PostgreSQL support was “on the way,” meaning incomplete and barely tested. Fast forward to May 2022, and the Postgres train has pulled into the station.
YugaByteDB 1.0 was built on top of an enhanced fork of the RocksDB key-value store. It used a log-structured, key-to-document storage engine, had a pluggable API layer, used Raft for cluster consensus, and used hybrid logical clock (HLC) timestamps and Network Time Protocol (NTP) clock synchronization for node time synchronization. Only the core functionality of YugaByteDB 1.0 was open source; I reviewed an enterprise version that included proprietary pieces, such as the YugaWare orchestration layer.
Currently, in YugabyteDB 2.13, the PostgreSQL support is quite advanced (but not completely done). The product is now entirely open source (Apache 2.0), although enterprises can (and do) buy a support contract for the Kubernetes-based Yugabyte Platform, and anyone can create paid clusters on the Yugabyte Cloud that run on Amazon Web Services (AWS) or Google Cloud Platform (GCP). Anyone can also create a free two-CPU one-node “cluster” on the Yugabyte Cloud for exploration purposes. At this point more than a million YugabyteDB clusters have been deployed.
YugabyteDB directly competes with other distributed SQL transactional databases, such as Google Cloud Spanner, Amazon Aurora, and CockroachDB. To a lesser extent, it also competes with traditional transactional databases, such as Oracle Database, SQL Server, and IBM DB2, as people move their database loads to the cloud and shift their application architectures to microservices.
YugabyteDB architecture
The year after I wrote my review of YugabyteDB 1.0, Karthik Ranganathan, co-founder and CTO of Yugabyte, wrote a series of technical articles about the company’s journey towards implementing a distributed version of PostgreSQL. One of the most interesting is “6 technical challenges developing a distributed SQL database.”
To summarize, the Yugabyte engineering team looked at Google Cloud Spanner and Amazon Aurora, and decided that they wanted to take a hybrid approach, emulating the horizontal scalability and geo-distribution of Spanner and the PostgreSQL-compatibility query layer of Amazon Aurora. They chose PostgreSQL compatibility and not MySQL, partly because of the rising popularity of PostgreSQL and partly because PostgreSQL has a more permissive license. (And yes, the fact that Oracle owns MySQL did enter into the calculations.)
Yugabyte chose the Raft cluster consensus algorithm rather than Paxos, with a leader lease mechanism that would allow the database to serve from the tablet leader without requiring a round trip, and chose a monotonic clock instead of a real-time clock. (Spanner uses TrueTime, which requires atomic clocks and GPS.) Yugabyte decided to use hybrid logical clocks (HLC), which solve the synchronization problem by combining physical time clocks that are coarsely synchronized using NTP with Lamport clocks that track causal relationships.
Yugabyte initially tried to rewrite the PostgreSQL API. After five months they gave up on that and re-used PostgreSQL’s query layer code. That had its own problems, but the company got there in the end.
YugabyteDB is comprised of two logical layers, each of which is a distributed service that runs on multiple nodes (or pods in case of Kubernetes). Yugabyte Query Layer (YQL) forms the upper layer of YugabyteDB that applications interact with using client drivers.
DocDB, a Google Spanner-inspired, high-performance, distributed document store, serves as the lower layer. Here user tables are implicitly managed as multiple shards, called tablets. This architecture gives four benefits: transparent sharding of tables, replication of shard data, transactions across shards (aka distributed transactions), and document-based persistence of rows. The details of how this works for various cases are outlined in this article (YugabyteDB storage layer).
Yugabyte SQL (YSQL) sits on top of DocDB as shown in the diagram below. The eye-watering details of how this works are given in a second article (YugabyteDB query layer). Suffice it to say that there was significant effort to implement system catalog management, user table management, the read and write IO Path, and mapping SQL tables to a document store.
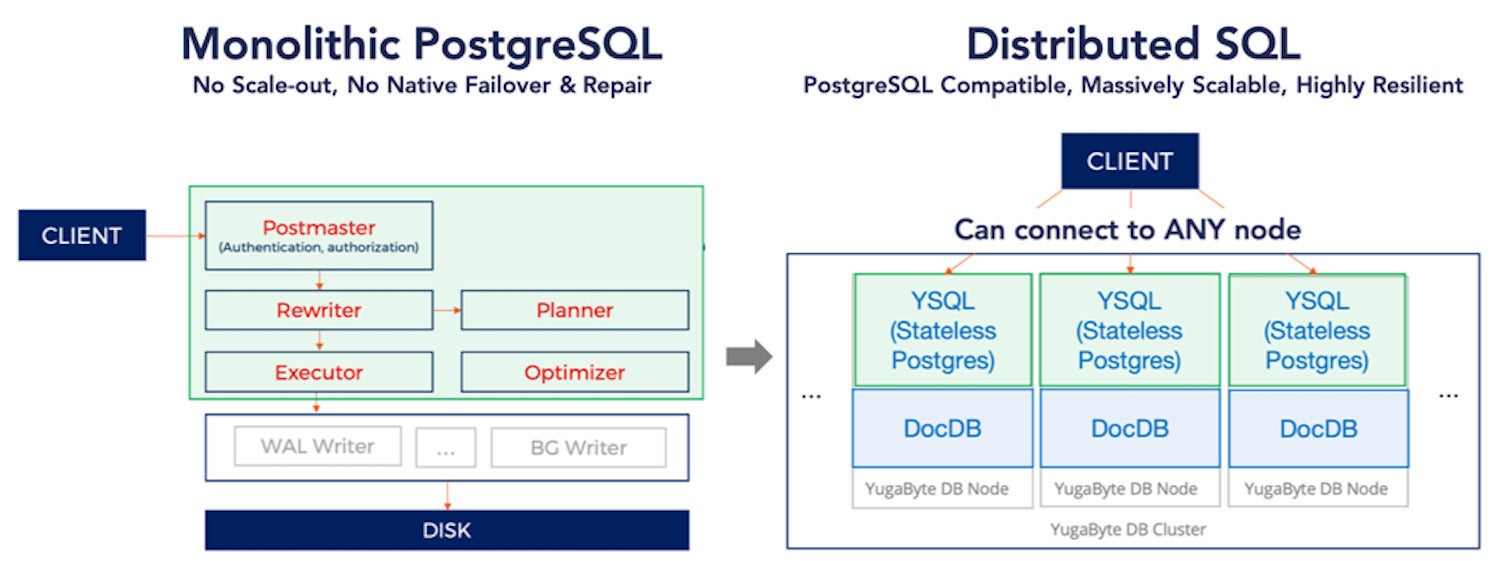 IDG
IDG
The YSQL layer of YugabyteDB is a non-trivial partitioning of the PostgreSQL query layer designed for scalability and resilience as well as compatibility.
What’s new in YugabyteDB 2.13
The short summary of the improvements in YugabyteDB 2.13 is that it delivers improved database performance, a better developer experience, and extended security and compliance. These areas break down into a bunch of discrete improvements.
- Materialized views create and store a pre-computed dataset derived from a query specification in order to reduce future query times by reducing data access and complex query computations.
- By keeping the metadata related to transactions within the same region, YugabyteDB eliminates cross-network latency and improves performance for region-local transactions.
- Operators can ensure that backups of data stay within the same cloud regions in order to reduce cloud storage data transfer costs and help organizations comply with complex data regulations, such as GDPR.
- YugabyteDB Cloud Shell lets developers connect to YugabyteDB using any modern browser. (I used this heavily in my testing.)
- Support for MyBatis and Dapper ORM tools.
- Developers have access to fully automated, integrated, cloud-native development workflows that can be preconfigured with YugabyteDB using cloud-based developer environments, Gitpod, and GitHub Codespaces.
- SOC 2 Type 1 security accreditation.
- Key management with HashiCorp Vault.
- Monitoring with Imperva Cloud Data Protection.
There are more improvements listed here and here.
Yugabyte TPC-C and Jepsen testing
In February 2022, Yugabyte ran a successful TPC-C transaction processing benchmark with 100,000 warehouses, using a cluster of 63 instances each c5d.12xlarge (48 vCPUs, 96 GB RAM). Throughput was 630K operations per second with a client-side latency for new orders of ~54 ms. That's an impressive demonstration of scale-out. For comparison, however, CockroachDB can process 1.68M tpmC with 140,000 warehouses, using a cluster of 81 nodes each c5d.9xlarge (36 vCPUs, 72 GB RAM), which is even more impressive.
Yugabyte has also been doing Jepsen testing. Kyle Kingsbury, the brains behind the Jepsen tests, is notoriously fussy about his results. In 2019 Yugabyte posted that “YSQL passed official Jepsen tests relatively easily.” Kyle responded on Twitter that no, it hadn’t: There were unresolved issues in non-transactional schema changes. Yugabyte’s blog post about the YugabyteDB 2.0 release later that year has an edit that acknowledges the problem, and the issue was resolved in YugabyteDB 2.1.3 in May 2020. So at this point it looks like YugabyteDB actually is Jepsen-certified.
Creating a Yugabyte Cloud cluster
There are three basic deployment options for YugabyteDB, referred to in the documentation as Yugabyte Core (open source; install from tarball, Helm chart, or Docker image), Yugabyte Anywhere (subscription; Kubernetes-based), and Yugabyte Managed (cloud). The three options are compared here.
I concentrated on Yugabyte Managed, since that has all the features and requires a minimum of setup. I initially created an always-free, one-node “cluster,” with an eye towards running a tutorial in the new YugabyteDB Cloud Shell.
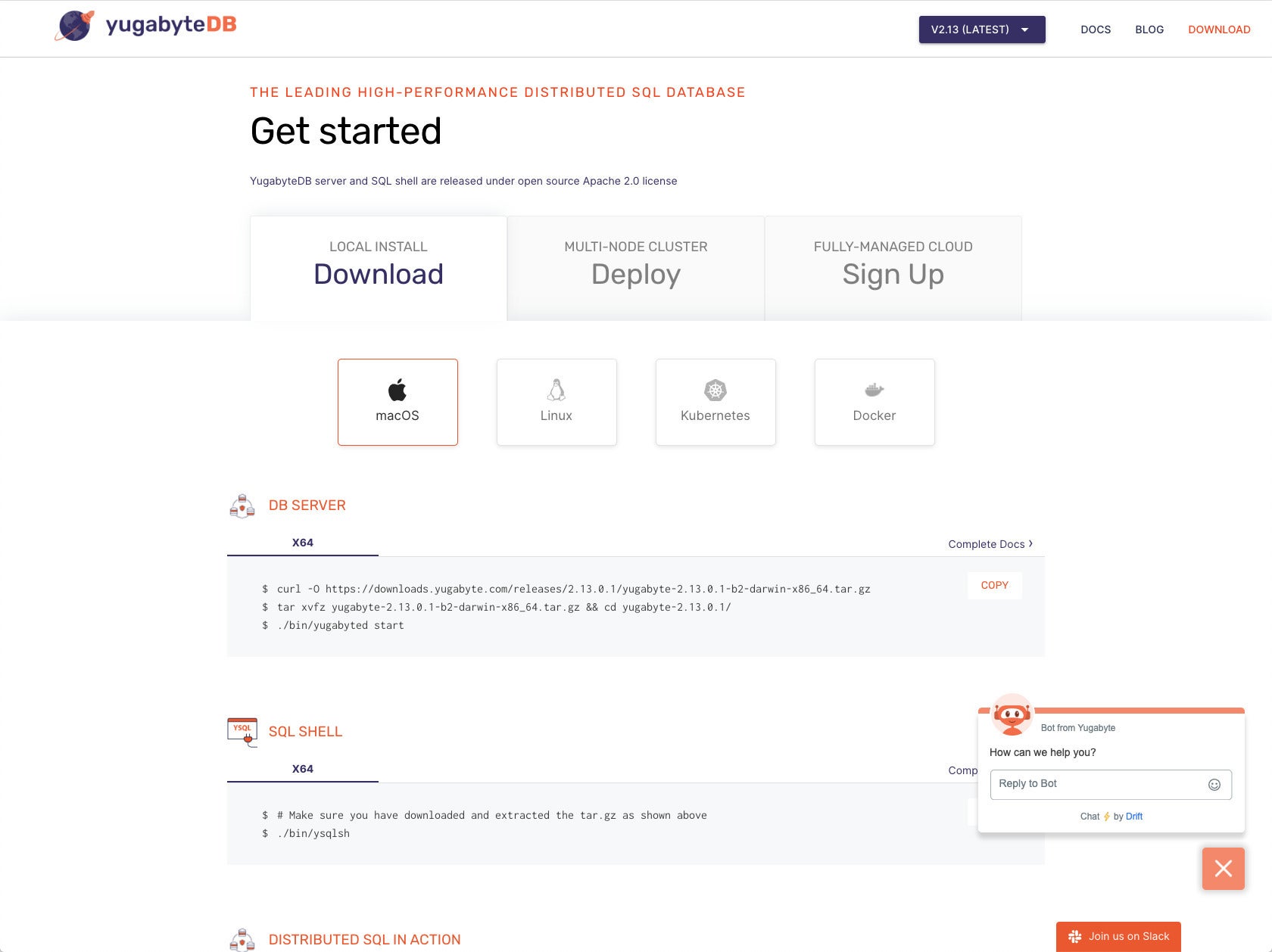 IDG
IDG
There are three high-level options for installing YugabyteDB, with multiple methods that depend on your target operating system and container choice.
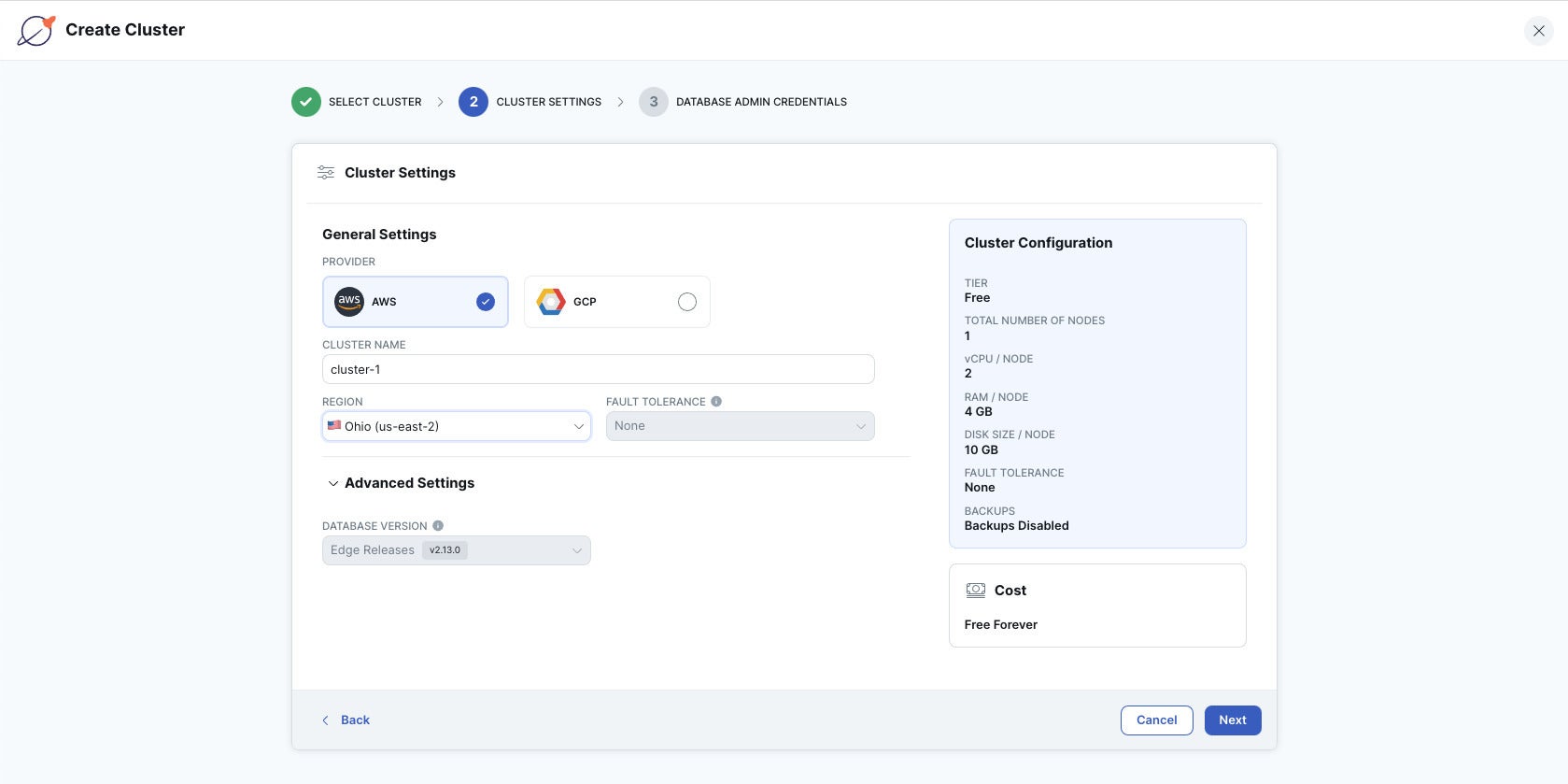 IDG
IDG
Creating a free-forever YugabyteDB cluster. This cluster has one node with two vCPUs, four GB of RAM, and 10 GB of disk space.
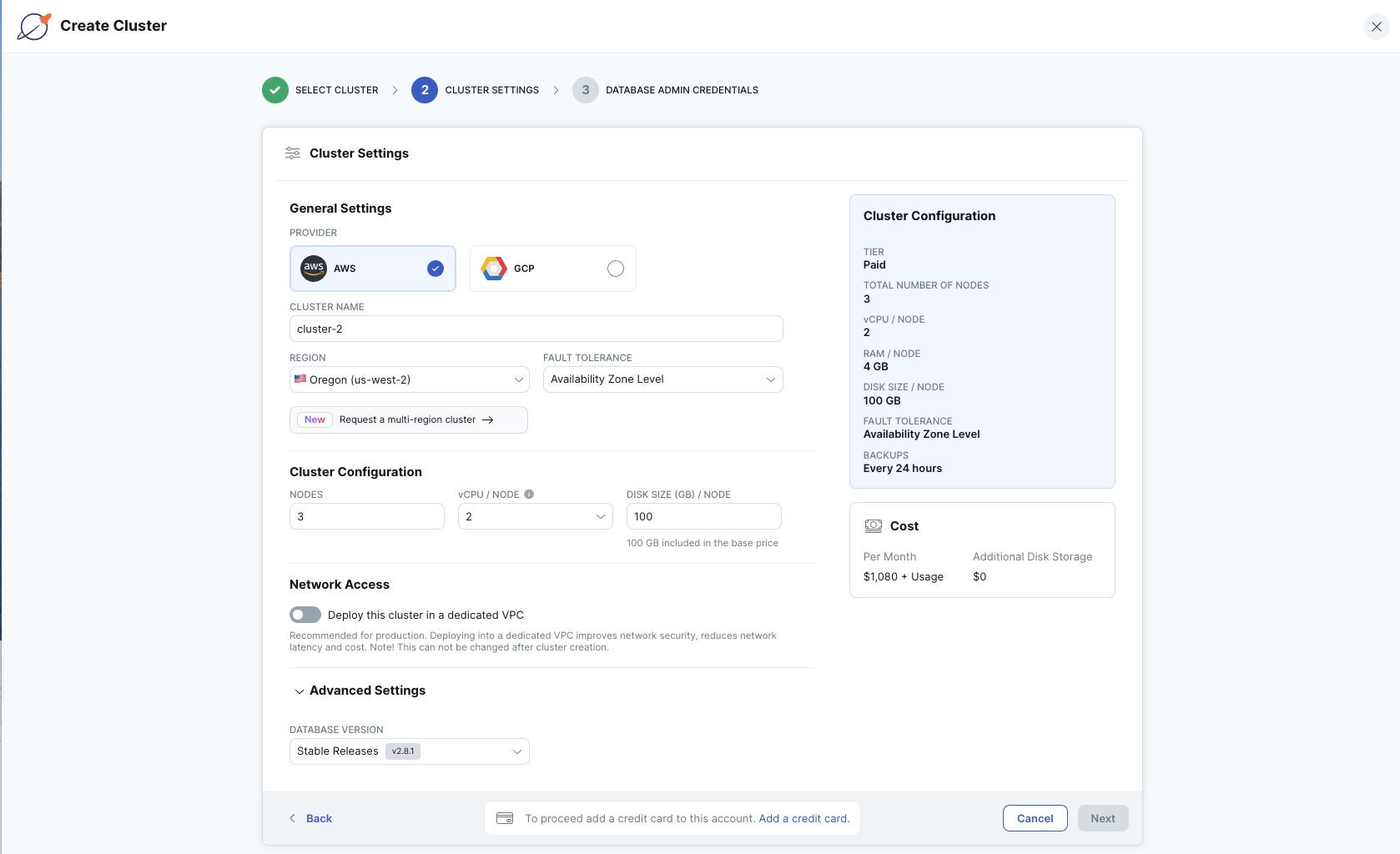 IDG
IDG
Creating a paid three-node cluster in Yugabyte Cloud. All of the options are open to the user for self-service, except that if you want a multi-region cluster you must submit a ticket and have VPCs in all of the requested regions. You can choose from the stable release or the edge release under advanced settings; if you want to use the edge release in production you need to contact support for approval. My vCPUs per node are limited to 16 or fewer; I imagine that enabling larger nodes would require a support request. The prices are the same on GCP and AWS, and across all regions; fault-tolerance triples the price.
Exercising Yugabyte SQL
With one minor exception that generated a beta warning, everything in the command-line Yugabyte SQL tutorial just worked. That includes a GIN index (generalized inverted index) for fast access to elements inside a JSONB or text field. I was disappointed to discover that Yugabyte doesn’t yet support GiST (generalized search tree) indexes, which are needed to make geospatial queries with the PostGIS extension run fast.
 IDG
IDG
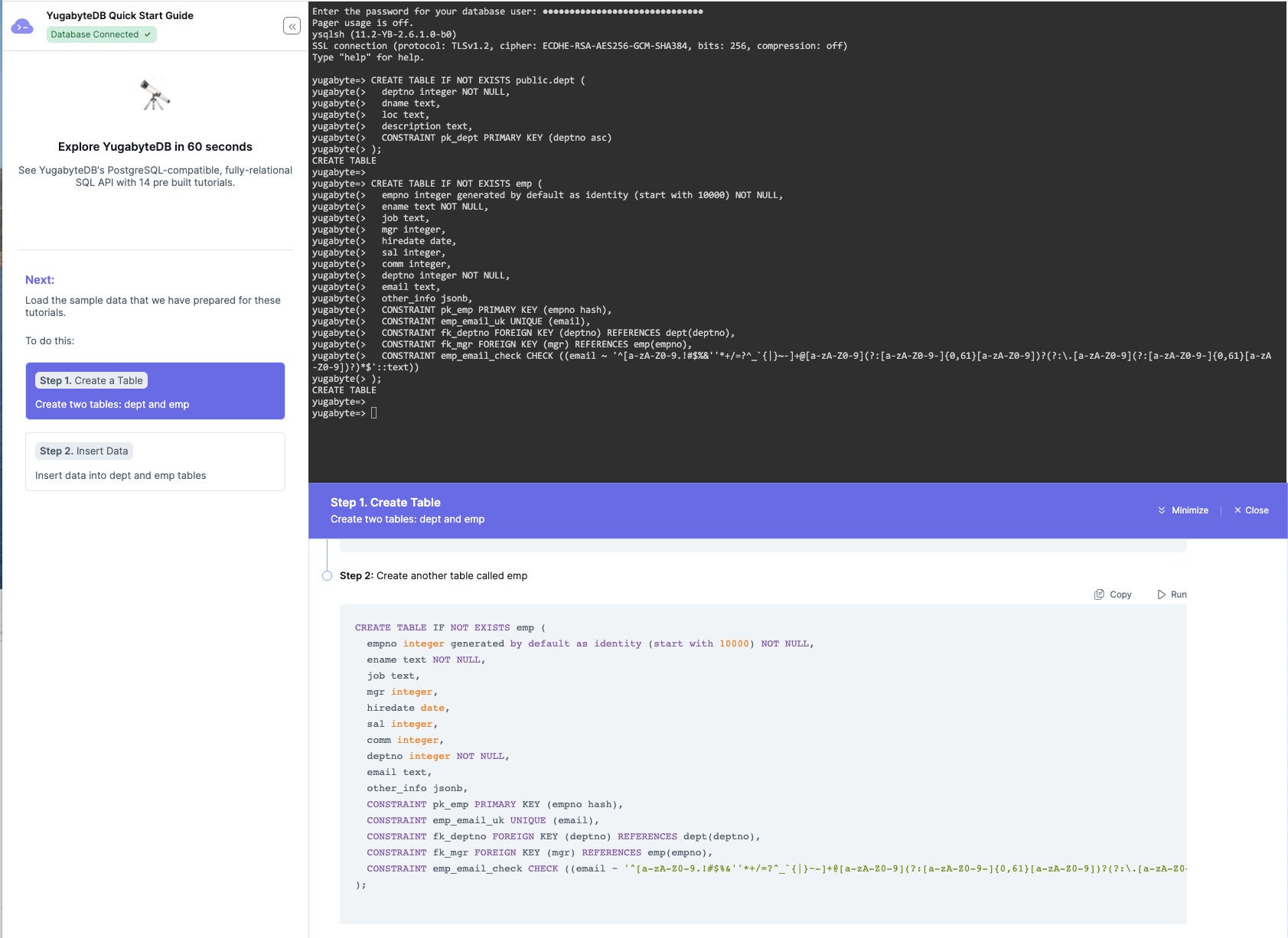
Creating two tables with near-standard PostgreSQL DDL. The tables include some fairly sophisticated constraints, including foreign keys and a check constraint with a regular expression. Note the use of hash indexes, for unordered data, as well as the usual ascending and descending indexes.
 IDG
IDG
Inserting data into the new tables. Note the use of “skills” values in the other_info JSONB field in the emp table. We’ll demonstrate using a GIN index to query these later on.
 IDG
IDG
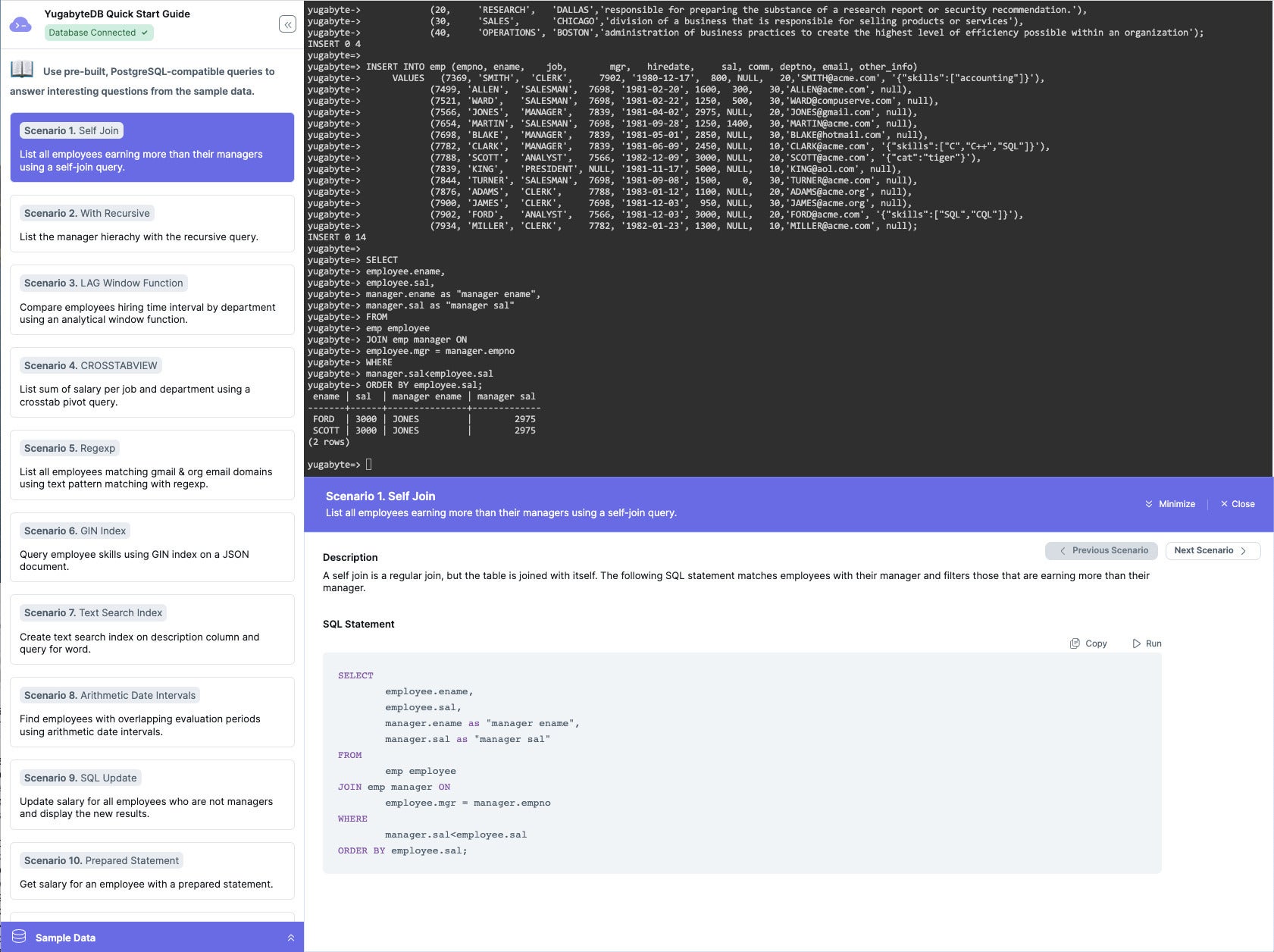
This SELECT query uses a self-join to find all employees who have higher salaries than their managers.
 IDG
IDG
This is a fairly advanced analytical query using the LAG, COALESCE, and WINDOW functions to determine the hiring date interval between employees within each department.
 IDG
IDG
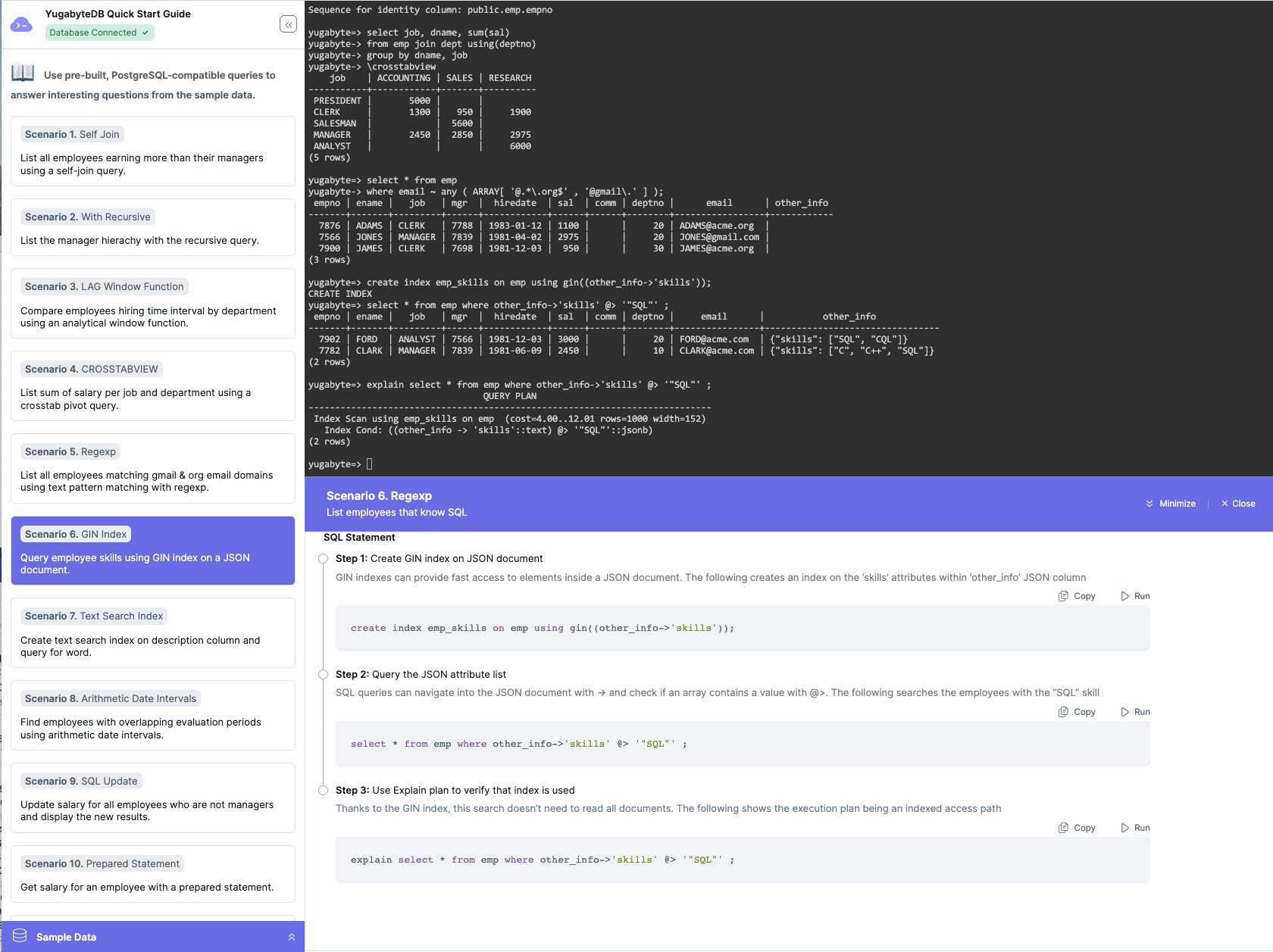
Here we create a GIN text index on a JSONB field and use it to perform a fast search using an index scan rather than performing a complete table scan.
 IDG
IDG
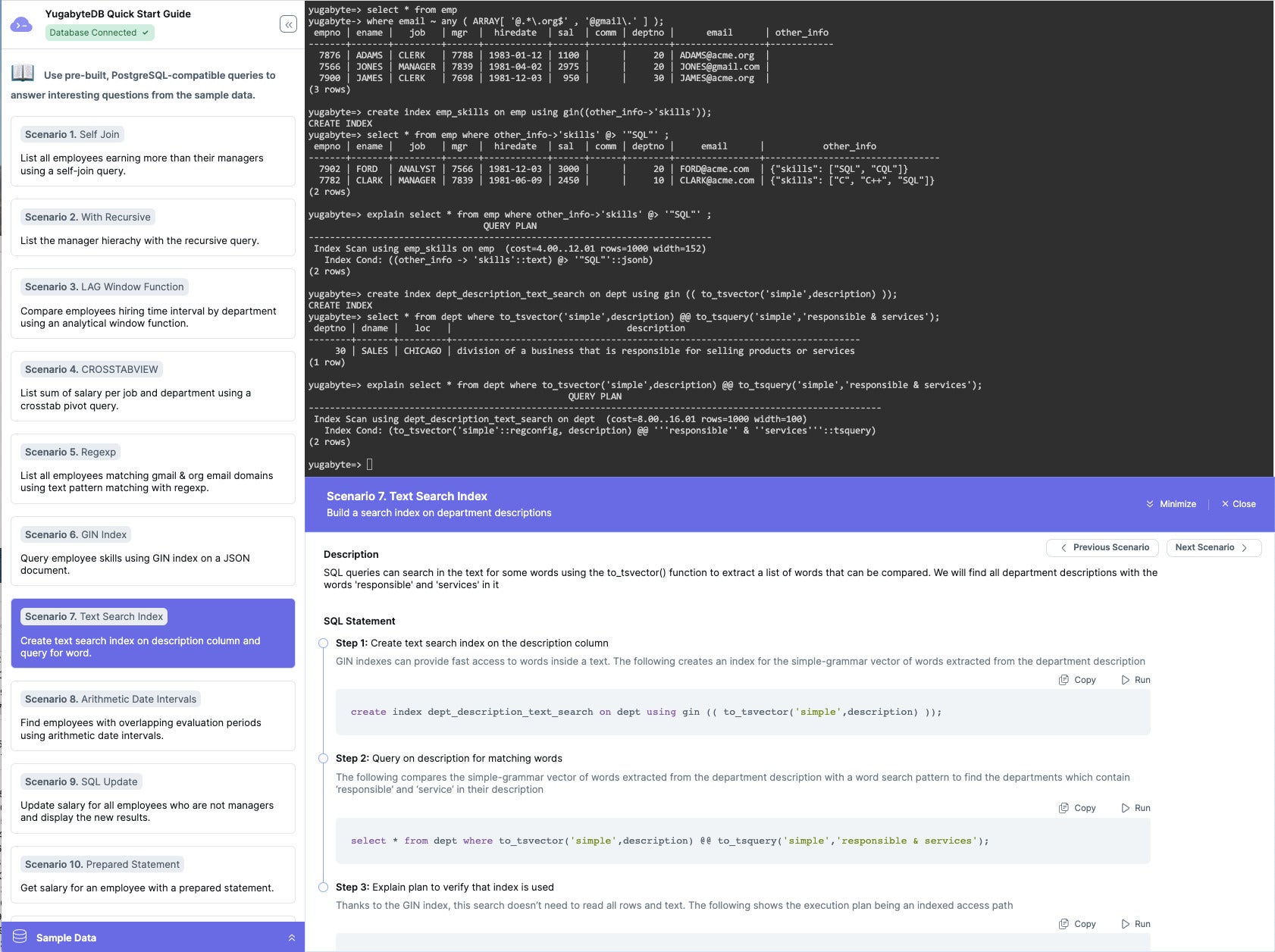
GIN indexes are applicable to any text field, not just JSONB fields. Here we combine a GIN index with the to_tsvector() function. The SELECT statement then uses an index scan to find the desired text results. The to_tsvector() function parses a textual document into tokens, reduces the tokens to lexemes, and returns a tsvector that lists the lexemes together with their positions in the document, as explained in the PostgreSQL documentation.
 IDG
IDG
YSQL supports both prepared statements and stored procedures. This stored procedure transfers some of the commission from one employee to another safely.
 IDG
IDG
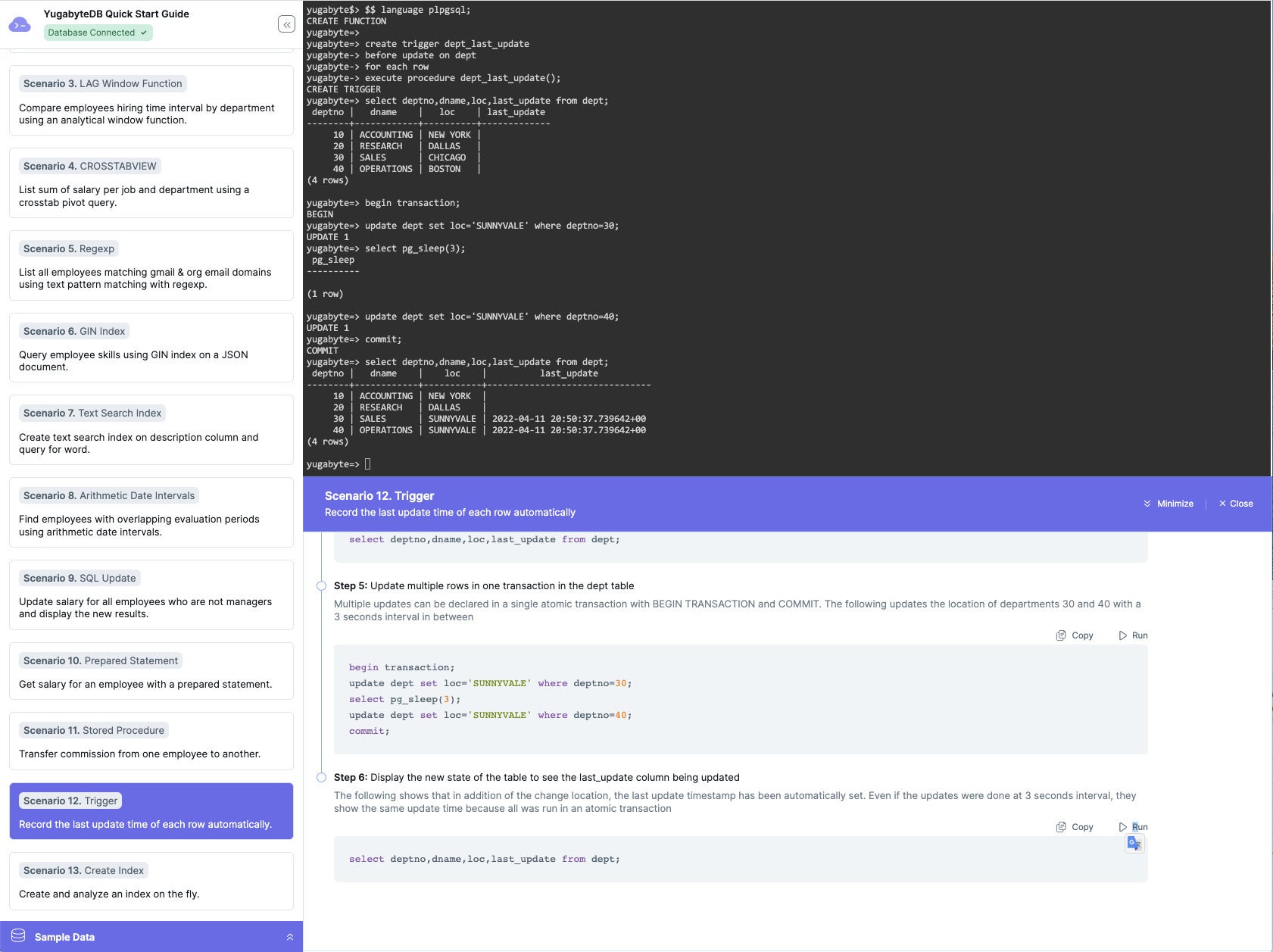
Here we demonstrate triggers and transactions, as well as the pg_ sleep() function.
 IDG
IDG
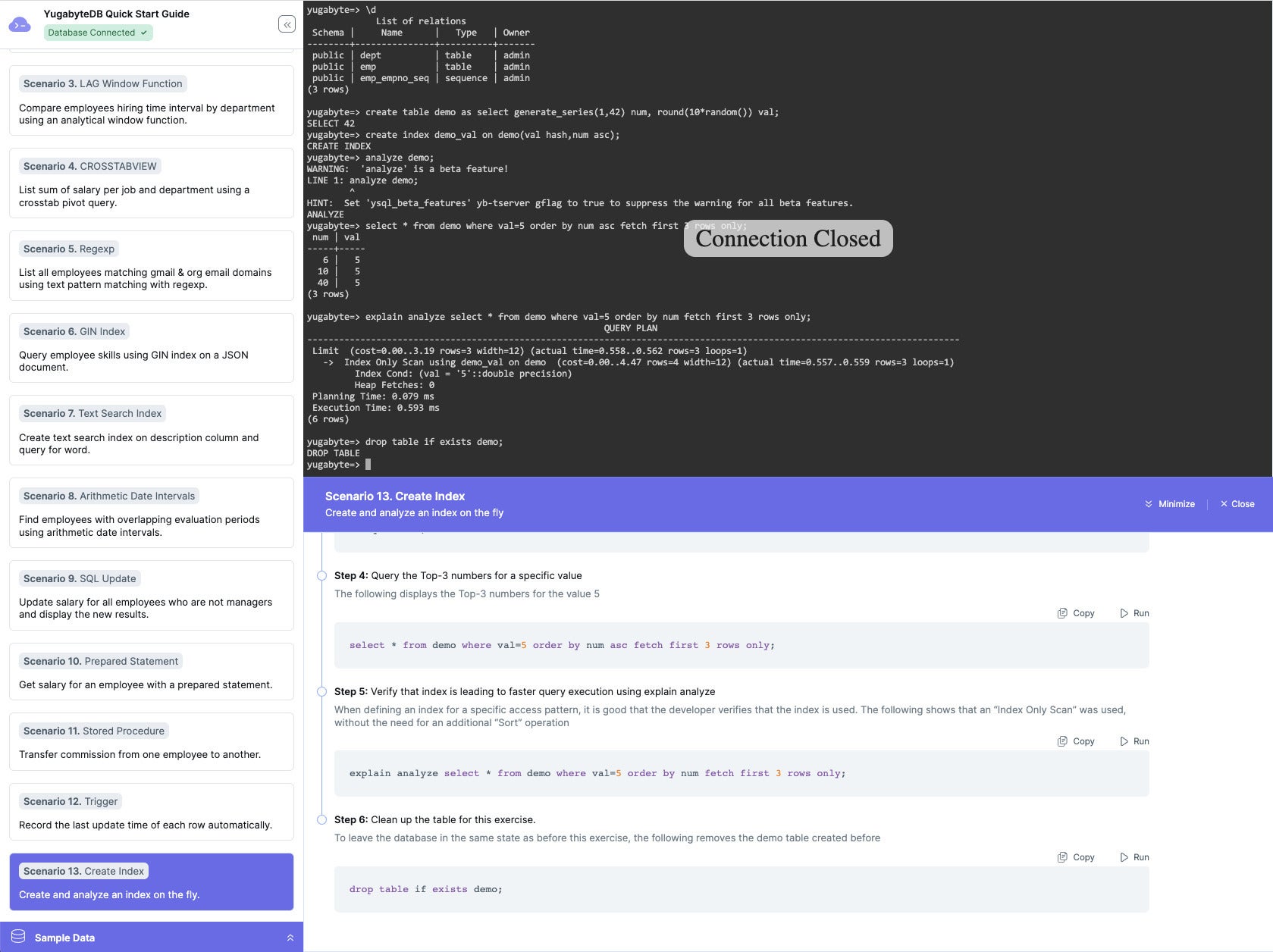
Here we generate a table, create an index, analyze the table, query the table for the first three values that equal five, and show that the query uses an index-only scan.
 IDG
IDG
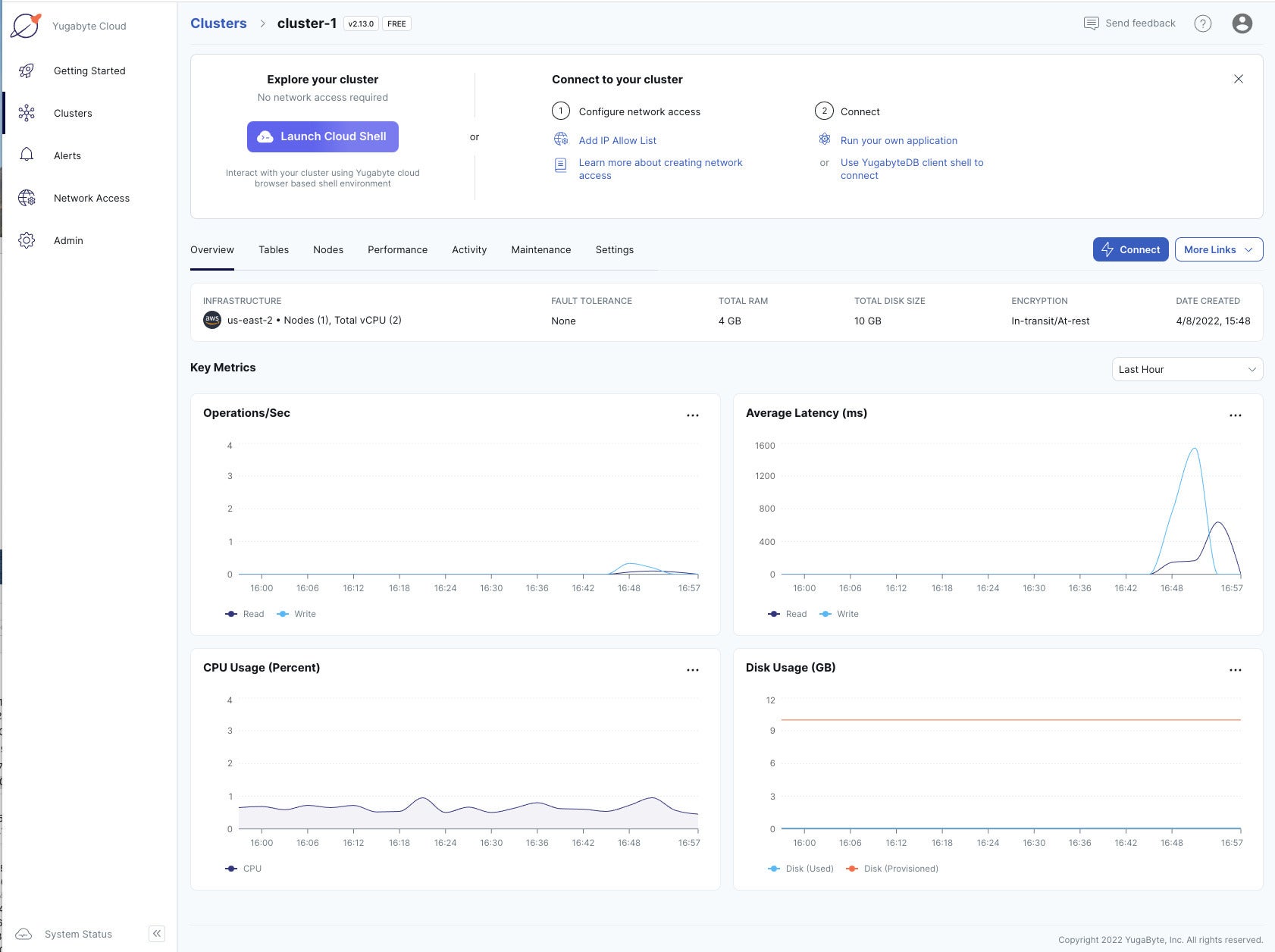
This dashboard shows the metrics for the Yugabyte Cloud cluster we’ve been using for the demonstration SQL queries. The high latencies were for the DDL queries that created tables and indexes. The CPU usage stayed low.