As a specification, the Jakarta Persistence API (formerly Java Persistence API) is concerned with persistence, which loosely means any mechanism by which Java objects outlive the application process that created them. Not all Java objects need to be persisted, but most applications persist key business objects. The JPA specification lets you define which objects should be persisted, and how they are persisted in your Java applications.
By itself, JPA is not a tool or framework; rather, it defines a set of concepts that guide implementers. While JPA's object-relational mapping (ORM) model was originally based on Hibernate, it has since evolved. Likewise, while JPA was originally intended for use with relational databases, some JPA implementations have been extended for use with NoSQL datastores. A popular framework that supports JPA with NoSQL is EclipseLink, the reference implementation for JPA 3.
The core idea behind JPA as opposed to JDBC, is that for the most part, JPA lets you avoid the need to “think relationally." In JPA, you define your persistence rules in the realm of Java code and objects, whereas JDBC requires you to manually translate from code to relational tables and back again.
Popular JPA implementations like Hibernate and EclipseLink now support JPA 3. Migrating from JPA 2 to JPA 3 involves some namespace changes, but otherwise the changes are under-the-hood performance gains.
JPA and Hibernate
Because of their intertwined history, Hibernate and JPA are frequently conflated. However, like the Java Servlet specification, JPA has spawned many compatible tools and frameworks. Hibernate is just one of many JPA tools.
Developed by Gavin King and first released in early 2002, Hibernate is an ORM library for Java. King developed Hibernate as an alternative to entity beans for persistence. The framework was so popular, and so needed at the time, that many of its ideas were adopted and codified in the first JPA specification.
Today, Hibernate ORM is one of the most mature JPA implementations, and still a popular option for ORM in Java. The latest release as of this writing, Hibernate ORM 6, implements JPA 2.2. Additional Hibernate tools include Hibernate Search, Hibernate Validator, and Hibernate OGM, which supports domain-model persistence for NoSQL.
What is Java ORM?
While they differ in execution, every JPA implementation provides some kind of ORM layer. In order to understand JPA and JPA-compatible tools, you need to have a good grasp on ORM.
Object-relational mapping is a task–one that developers have good reason to avoid doing manually. A framework like Hibernate ORM or EclipseLink codifies that task into a library or framework, an ORM layer. As part of the application architecture, the ORM layer is responsible for managing the conversion of software objects to interact with the tables and columns in a relational database. In Java, the ORM layer converts Java classes and objects so that they can be stored and managed in a relational database.
By default, the name of the object being persisted becomes the name of the table, and fields become columns. Once the table is set up, each table row corresponds to an object in the application. Object mapping is configurable, but defaults tend to work, and by sticking with defaults, you avoid having to maintain configuration metadata.
Figure 1 illustrates the role of JPA and the ORM layer in application development.
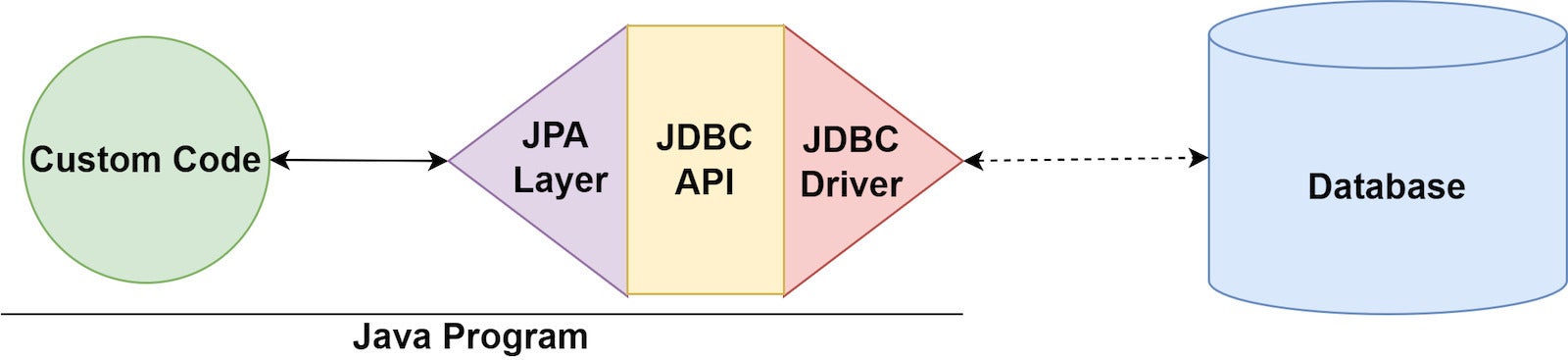{kind=link}
Figure 1. JPA and the Java ORM layer.
Configuring the Java ORM layer
When you set up a new project to use JPA, you will need to configure the datastore and JPA provider. You'll configure a datastore connector to connect to your chosen database (SQL or NoSQL). You'll also include and configure the JPA provider, which is a framework such as Hibernate or EclipseLink. While you can configure JPA manually, many developers choose to use Spring's out-of-the-box support. We'll take a look at both manual and Spring-based JPA installation and setup shortly.
Data persistence in Java
From a programming perspective, the ORM layer is an adapter layer: it adapts the language of object graphs to the language of SQL and relational tables. The ORM layer allows object-oriented developers to build software that persists data without ever leaving the object-oriented paradigm.
When you use JPA, you create a map from the datastore to your application's data model objects. Instead of defining how objects are saved and retrieved, you define the mapping between objects and your database, then invoke JPA to persist them. If you're using a relational database, much of the actual connection between your application code and the database will then be handled by JDBC.
As a specification, JPA provides metadata annotations, which you use to define the mapping between objects and the database. Each JPA implementation provides its own engine for JPA annotations. The JPA spec also provides the PersistanceManager or EntityManager, which are the key points of contact with the JPA system (wherein your business logic code tells the system what to do with the mapped objects).
To make all of this more concrete, consider Listing 1, which is a simple data class for modeling a musician.
Listing 1. A simple data class in Java
public class Musician {
private Long id;
private String name;
private Instrument mainInstrument;
private ArrayList performances = new ArrayList();
public Musician( Long id, String name){ /* constructor setters... */ }
public void setName(String name){
this.name = name;
}
public String getName(){
return this.name;
}
public void setMainInstrument(Instrument instr){
this.instrument = instr;
}
public Instrument getMainInstrument(){
return this.instrument;
}
// ...Other getters and setters...
}
The Musician class in Listing 1 is used to hold data. It can contain primitive data such as the name field. It can also hold relations to other classes such as mainInstrument and performances.
Musician's reason for being is to contain data. This type of class is sometimes known as a DTO, or data transfer object. DTOs are a common feature of software development. While they hold many kinds of data, they do not contain any business logic. Persisting data objects is a ubiquitous challenge in software development.
Data persistence with JDBC
One way to save an instance of the Musician class to a relational database would be to use the JDBC library. JDBC is a layer of abstraction that lets an application issue SQL commands without thinking about the underlying database implementation.
Listing 2 shows how you could persist the Musician class using JDBC.
Listing 2. JDBC inserting a record
Musician georgeHarrison = new Musician(0, "George Harrison");
String myDriver = "org.gjt.mm.mysql.Driver";
String myUrl = "jdbc:mysql://localhost/test";
Class.forName(myDriver);
Connection conn = DriverManager.getConnection(myUrl, "root", "");
String query = " insert into users (id, name) values (?, ?)";
PreparedStatement preparedStmt = conn.prepareStatement(query);
preparedStmt.setInt (1, 0);
preparedStmt.setString (2, "George Harrison");
preparedStmt.setString (2, "Rubble");
preparedStmt.execute();
conn.close();
// Error handling removed for brevity
The code in Listing 2 is fairly self-documenting. The georgeHarrison object could come from anywhere (front-end submit, external service, etc.), and has its ID and name fields set. The fields on the object are then used to supply the values of an SQL insert statement. (The PreparedStatement class is part of JDBC, offering a way to safely apply values to an SQL query.)
While JDBC provides the control that comes with manual configuration, it is cumbersome compared to JPA. To modify the database, you first need to create an SQL query that maps from your Java object to the tables in a relational database. You then have to modify the SQL whenever an object signature changes. With JDBC, maintaining the SQL becomes a task in itself.
Data persistence with JPA
Now consider Listing 3, where we persist the Musician class using JPA.
Listing 3. Persisting George Harrison with JPA
Musician georgeHarrison = new Musician(0, "George Harrison");
musicianManager.save(georgeHarrison);
Listing 3 replaces the manual SQL from Listing 2 with a single line, entityManager.save(), which instructs JPA to persist the object. From then on, the framework handles the SQL conversion, so you never have to leave the object-oriented paradigm.
Metadata annotations in JPA
The magic in Listing 3 is the result of a configuration, which is created using JPA's annotations. Developers use annotations to inform JPA which objects should be persisted, and how they should be persisted.
Listing 4 shows the Musician class with a single JPA annotation.
Listing 4. JPA's @Entity annotation
@Entity
public class Musician {
// ..class body
}
Persistent objects are sometimes called entities. Attaching @Entity to a class like Musician informs JPA that this class and its objects should be persisted.
Configuring JPA
Like most modern frameworks, JPA embraces coding by convention (also known as convention over configuration), in which the framework provides a default configuration based on industry best practices. As one example, a class named Musician would be mapped by default to a database table called Musician.
The conventional configuration is a timesaver, and in many cases it works well enough. It is also possible to customize your JPA configuration. As an example, you could use JPA's @Table annotation to specify the table where the Musician class should be stored.
Listing 5. JPA's @Table annotation
@Entity
@Table(name="musician")
public class Musician {
// ..class body
}
Listing 5 tells JPA to persist the entity (the Musician class) to the Musician table.
Primary key
In JPA, the primary key is the field used to uniquely identify each object in the database. The primary key is useful for referencing and relating objects to other entities. Whenever you store an object in a table, you will also specify the field to use as its primary key.
In Listing 6, we tell JPA what field to use as Musician's primary key.
Listing 6. Specifying the primary key
@Entity
public class Musician {
@Id
private Long id;
In this case, we've used JPA's @Id annotation to specify the id field as Musician's primary key. By default, this configuration assumes the primary key will be set by the database--for instance, when the field is set to auto-increment on the table.
JPA supports other strategies for generating an object's primary key. It also has annotations for changing individual field names. In general, JPA is flexible enough to adapt to any persistence mapping you might need.
CRUD operations
Once you've mapped a class to a database table and established its primary key, you have everything you need to create, retrieve, delete, and update that class in the database. Calling entityManager.save() will create or update the specified class, depending on whether the primary-key field is null or applies to en existing entity. Calling entityManager.remove() will delete the specified class.
Entity relationships
Simply persisting an object with a primitive field is only half the equation. JPA also lets you manage entities in relation to one another. Four kinds of entity relationships are possible in both tables and objects:
- One-to-many
- Many-to-one
- Many-to-many
- One-to-one
Each type of relationship describes how an entity relates to other entities. For example, the Musician entity could have a one-to-many relationship with Performance, an entity represented by a collection such as List or Set.
If the Musician included a Band field, the relationship between these entities could be many-to-one, implying a collection of Musicians on the single Band class. (Assuming each musician only performs in a single band.)
If Musician included a BandMates field, that could represent a many-to-many relationship with other Musician entities.
Finally, Musician might have a one-to-one relationship with a Quote entity, used to represent a famous quote: Quote famousQuote = new Quote().
Defining relationship types
JPA has annotations for each of of its relationship mapping types. Listing 7 shows how you might annotate the one-to-many relationship between Musician and Performances.
Listing 7. Annotating a one-to-many relationship
public class Musician {
@OneToMany
@JoinColumn(name="musicianId")
private List performances = new ArrayList();
//...
}
One thing to notice is that the @JoinColumn tells JPA what column on the Performance table will map to the Musician entity. Each performance will be associated to a single Musician, which is tracked by this column. When JPA loads a Musician or a Performance into the database, it will use this information to reconstitute the object graph.
Entity states and detached entities
An entity is the general name for an object whose persistence is mapped with ORM. The entities in your running application will always be in one of four states: transient, managed, detached, and removed.
One situation you’ll encounter in JPA is that of a detached entity. This simply means that the objects you are dealing with have departed from what is in the datastore backing them, and the session that backs them has been closed. In other words, JPA wants to keep the objects up-to-date, but it’s unable to. You can reattach a detached entity by calling entityManager.merge() on the entity.
Any object that is not persistent is transient. The object is only a potential entity at that point. Once entityManager.persist() is called on it, it becomes a persistent entity.
A managed object is a persistent entity.
When an entity has been deleted from the datastore, but still exists as a live object, it is said to be in the removed state.
Vlad Mihalcea has written a fine discussion of entity states, along with the subtle differences between JPA’s EntityManager and Hibernate’s Session classes for managing them.
What is EntityManager.flush() for?
Many developers new to JPA wonder about the purpose of the EntityManager.flush() method. The JPA manager will cache the operations required to keep the persisted state of the entities consistent with the database, and batch them for efficiency.
Sometimes, though, you will need to manually cause the JPA framework to enact the operations required to push the entities to the database. This could be to cause a database trigger to execute, for example. In that case, you can use the flush() method, and all entity state that hasn’t been persisted will immediately be sent to the database.
Fetching strategies
In addition to knowing where to place related entities in the database, JPA needs to know how you want them loaded. Fetching strategies tell JPA how to load related entities. When loading and saving objects, a JPA framework must provide the ability to finetune how object graphs are handled. For instance, if the Musician class has a bandMate field (as shown in Listing 7), loading george could cause the entire Musician table to be loaded from the database!
You need to be able to define lazy loading of related entities–recognizing, of course, that relationships in JPA can be eager or lazy. You can use annotations to customize your fetching strategies, but JPA's default configuration often works out of the box, without changes:
- One-to-many: Lazy
- Many-to-one: Eager
- Many-to-many: Lazy
- One-to-one: Eager
JPA installation and setup
We'll conclude with a quick look at installing and setting up JPA for your Java applications. For this demonstration I'll use EclipseLink, the JPA reference implementation.
The common way to install JPA is to include a JPA provider into your project. Listing 8 shows how you would include EclipseLink as a dependency in your Maven pom.xml file.
Listing 8. Include EclipseLink as a Maven dependency
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>4.0.0-M3</version>
</dependency>
You will also need to include the driver for your database, as shown in Listing 9.
Listing 9. Maven dependency for a MySql connector
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
Next, you'll need to tell the system about your database and provider. This is done in the persistence.xml file, as shown in Listing 10.
Listing 10. Persistence.xml
http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="MyUnit" transaction-type="RESOURCE_LOCAL">
<properties>
<property name="jakarta.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/foo_bar"/>
<property name="jakarta.persistence.jdbc.user" value=""/>
<property name="jakarta.persistence.jdbc.password" value=""/>
<property name="jakarta.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
</properties>
</persistence-unit>
</persistence>
There are other ways to provide this information to the system, including programmatically. I recommend using the persistence.xml file because storing dependencies this way makes it very easy to update your application without modifying code.
Spring configuration for JPA
Using Spring will greatly ease the integration of JPA into your application. As an example, placing the @SpringBootApplication annotation in your application header instructs Spring to automatically scan for classes and inject the EntityManager as required, based on the configuration you've specified.
Listing 11 shows the dependencies to include if you want Spring's JPA support for your application.
Listing 11. Adding Spring JPA support in Maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.6.7</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.6.7</version>
</dependency>
When to use JPA
The question of whether to use JPA is a common source of analysis paralysis when designing a Java application. Especially when attempting to make up-front technology decisions, you don’t want to get data persistence—an essential and long-term factor—wrong.
To break this kind of paralysis, it’s useful to remember that applications can evolve into using JPA. You might build exploratory or prototype code using JDBC or a NoSQL library, then start adding in JPA. There’s no reason these solutions can’t coexist.
After being paralyzed by indecision, the next worst thing is to adopt JPA when the additional effort it implies will prevent a project from moving forward. JPA can be a win for overall system stability and maintainability, and those are wonderful goals for a more established project; however, sometimes simpler is better, especially at the beginning of a project.
If your team doesn't have the capacity to adopt JPA up front, consider putting it on your roadmap for the future.
Conclusion
Every application that deals with a database should define an application layer whose sole purpose is to isolate persistence code. As you've seen in this article, the Jakarta Persistence API introduces a range of capabilities and support for Java object persistence. Simple applications may not require all of JPA's capabilities, and in some cases the overhead of configuring the framework may not be merited. As an application grows, however, JPA's structure and encapsulation really earn their keep. Using JPA keeps your object code simple and provides a conventional framework for accessing data in Java applications.
Learn more about the Jakarta Persistence API and related technologies:
- What is JDBC? Introduction to Java Database Connectivity: An overview and guide to connecting to a database, handling SQL queries, and more with JDBC.
- Java persistence with JPA and Hibernate, Part 1: Modeling entities and relationships.
- Java persistence with JPA and Hibernate, Part 2: Many-to-many relationships and inheritance relationships.
- Should you use JPA for your next project?: Key questions that could help you decide.